cURL で web 上のコンテンツを自動ダウンロードする
$ curl http://example.com/index.html -O すればダウンロードできるとかいうけど、
実際はそんなうまくいかない場合もある。
某動画サイトで cURL つかって動画のダウンロードを上記要領でやったらうまくいかなかった。
Chrome の developer tool 使って、Network タブからどんな HTTP リクエストがやり取りされているか見てみた。
やたらリダイレクトされてた。
-L つければ余裕かとおもいきやそうでもなかった。
Header を偽装すれば行ける?いやいけない。
こまったのでいろいろ調べてたら、
Chrome にはユーザー操作で発生したリクエストを cURL コマンドで教えてくれる便利機能があった。
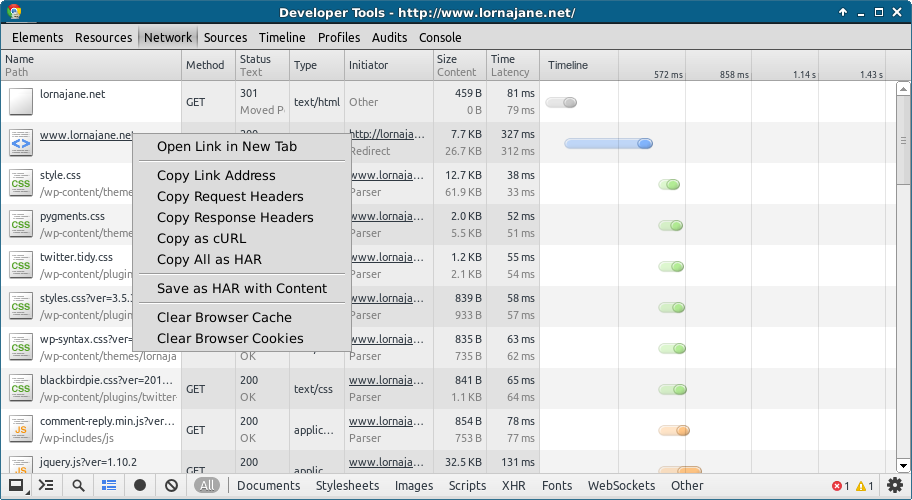
右クリックでコピーして terminal にペーストして Enter。
万事解決した。
とりあえず複雑な処理してたら -L つけて、
データ取得のために -O つければ幸せになれます。
HTML ソースから、ファイル名の規則とかディレクトリの構成を推測すれば、
欲しいものだけ連番ダウンロードできて幸せになれたりします。
ということで
めでたしめでたし。
実際はそんなうまくいかない場合もある。
某動画サイトで cURL つかって動画のダウンロードを上記要領でやったらうまくいかなかった。
Chrome の developer tool 使って、Network タブからどんな HTTP リクエストがやり取りされているか見てみた。
やたらリダイレクトされてた。
-L つければ余裕かとおもいきやそうでもなかった。
Header を偽装すれば行ける?いやいけない。
こまったのでいろいろ調べてたら、
Chrome にはユーザー操作で発生したリクエストを cURL コマンドで教えてくれる便利機能があった。
Chrome Feature: Copy as cURL
(LORNAJANE Blog より引用)
万事解決した。
とりあえず複雑な処理してたら -L つけて、
データ取得のために -O つければ幸せになれます。
HTML ソースから、ファイル名の規則とかディレクトリの構成を推測すれば、
欲しいものだけ連番ダウンロードできて幸せになれたりします。
ということで
curlコマンドで連番サイトの全データを取得する
もリンクしておきます。めでたしめでたし。
コメント
コメントを投稿